Roman Čerešňák is back with us today. He's the AWS Cloud Architect and AI/ML specialist who previously walked us through orchestrating serverless data pipelines with AWS Glue and MWAA. Today, he's tackling one of the most pressing challenges facing enterprises in 2026: keeping AI agent costs under control.
In this piece, he introduces AgentCore — a strategic framework for building AI agents that are economically sustainable:
• Why autonomous agents silently burn through budgets (and how to stop it) • The three-layer cognitive hierarchy that matches the right "brain" to the right task • Real-world savings, including how one fintech cut $450K annually
💡 If you are interested in getting hands-on with AWS Cloud environments – without any setup, cleanup, or extra cost – Educative Cloud Labsare a great way to do that. (You can also try a new new Cloud Lab Challenge to put your skills to the test).
Now over to Roman!
As we navigate 2026, the initial “wow factor” of Generative AI has matured into a demand for operational pragmatism. Enterprises are no longer satisfied with mere proofs of concept; they require a clear path to Return on Investment (ROI). Autonomous agents - systems capable of independent reasoning, planning, and tool use - represent the pinnacle of current AI capabilities. However, their greatest vulnerability lies in unpredictable operational costs.
Unlike a traditional chatbot that consumes tokens only for a direct response, an agent operating within the AgentCore framework goes through multiple cycles of reasoning, tool execution, and self-reflection. Without strict optimization, a single user request can inadvertently trigger a chain reaction of API calls costing several dollars. AgentCore is not just a collection of technical tricks; it is a comprehensive philosophy for managing digital intelligence in a fiscally responsible manner.
Architectural Pillars of AgentCore: Cognitive Tiering
The foundation of efficiency lies in deconstructing monolithic intelligence into specialized modules. By using the right “brain” for the right task, we eliminate the waste of using frontier models for trivial operations.
1.1. The Three-Layer Cognitive Hierarchy (L1, L2, L3)
AgentCore defines the cognitive stack as follows:
• L1 — The Sentry (Perception & Security Layer): Utilizes the smallest models (e.g., Llama-3–8B, GPT-4o-mini). Its role is to immediately check the input for PII (Personally Identifiable Information), toxicity, and semantic intent. If a user asks a trivial question, L1 handles it instantly, bypassing more expensive systems.
• L2 — The Worker (Operational Layer): This layer is tool-literate. It performs SQL queries, API calls, and processes documents via RAG. Models here (e.g., Gemini 1.5 Flash, Claude 3.5 Haiku) are optimized for speed and strict JSON formatting.
• L3 — The Architect (Strategic Layer): The “brain” of the system. Reserved for situations where logic fails or complex multi-modal reasoning is required. This layer runs on the most powerful frontier models available.
2. Intelligent Routing: The Semantic Gateway
At the heart of AgentCore is the Intelligent Router. Its primary task is to predict the “cognitive weight” of a task before it is dispatched to a model.
2.1. Router Decision Logic
The AgentCore Router employs a technique called Semantic Gating. Imagine it as a toll booth where the “cargo” (the prompt) is weighed.
1. Request Vectorization: The input is converted into a numerical vector. 2. Difficulty Classification: The Router compares the vector against historical success data of various models. 3. Model Assignment: If the probability of success for an L1 model is >90%, the task stops there. Otherwise, it is escalated.
Table 1: Router Decision Matrix
3. Token Management and Semantic Compression
In an ecosystem where you pay for every word, redundancy is the enemy. AgentCore introduces Contextual Hygiene to ensure models only see what they need.
3.1. Adaptive Context Pruning (ACP)
During long agentic conversations, the context window fills with “noise.” The ACP algorithm acts as an intelligent eraser:
• It identifies segments of the conversation history that are “resolved” (e.g., confirmation of data received). • It replaces these segments with a one-sentence summary. • This keeps the context window lean, reducing costs for every subsequent “turn” by up to 40%.
Providers like Anthropic and OpenAI now offer significant discounts for caching identical parts of a prompt. AgentCore automatically detects static portions (e.g., system instructions, tool definitions) and moves them to the beginning of the call to maximize the Cache Hit Rate.
Traditional Retrieval-Augmented Generation (RAG) is expensive because models must read long snippets of text that might be irrelevant. AgentCore implements Two-Stage RAG.
1. Stage 1: Low-Cost Retrieval: Use a cheap vector database to pull 30 potential candidates.
2. Stage 2: Reranking & Summarization: Instead of sending all 30 snippets to a flagship LLM, we use a Cross-Encoder (Reranker). This model sorts snippets by precision. The top 3 snippets are processed by an L1 model to extract only the sentences that directly answer the query. Only these cleaned sentences are sent to the final L3 model.
Result: A 70–90% reduction in input tokens without losing factual accuracy.
5. Fine-Tuning and Distillation (The Long-Game Strategy)
Once your agentic system reaches a certain volume, relying solely on general-purpose APIs becomes inefficient. AgentCore advocates for the transition to specialized adapters.
5.1. The Knowledge Distillation Pipeline
1. Teacher Model: Use the best model on the market to generate “Golden Answers” for your specific tasks. 2. Dataset Construction: AgentCore automatically collects these pairs and scrubs them for noise. 3. Student Training: Fine-tune a small model (Llama-3–8B or Mistral) on this data. 4. Inference Swap: Replace the expensive Teacher model with the specialized Student.
This process typically reduces marginal costs to near zero (if self-hosting) or by 95% via specialized serverless hosting.
6. FinOps: Real-Time AI Observability
AgentCore is incomplete without Observability. Managers must see where the “token burn” is happening in real-time.
6.1. Unit Economics: Cost Per Success (CPS)
Instead of tracking “cost per million tokens,” AgentCore tracks Cost Per Success (CPS).
• If an agent solves a problem in one step with a flagship model for $0.05, it is cheaper than a cheap model trying 10 times unsuccessfully for a total of $0.10.
• AgentCore assigns a Trace ID to every task, tracking cumulative costs across all models used in that specific reasoning chain.
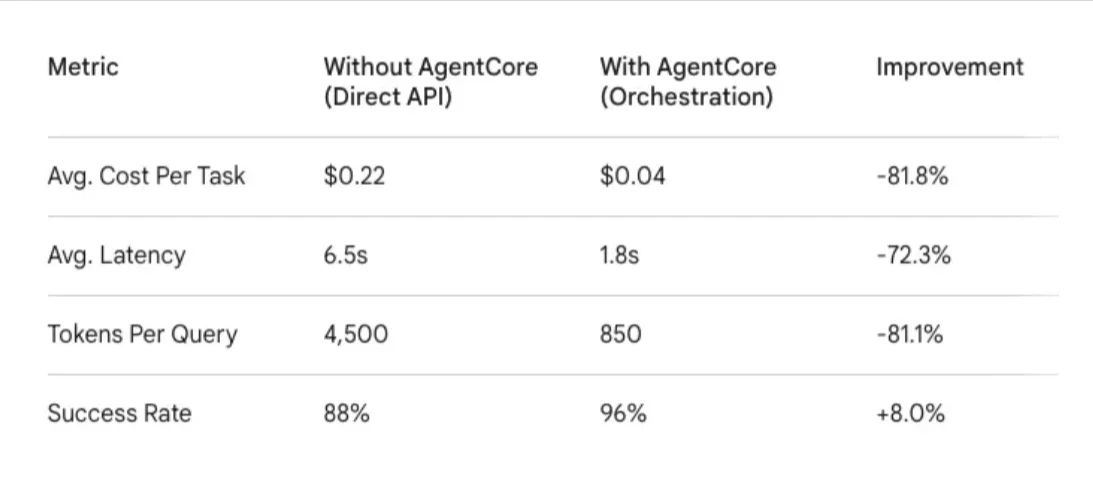
Table 2: Efficiency Comparison (Before vs. After AgentCore)
7. Case Studies: AgentCore in the Real World
7.1. Global Fintech Provider
A firm managing thousands of daily transactions used agents for fraud detection. Initially, every query was analyzed by GPT-4. By implementing the L1-Router and Semantic Caching, they found that 60% of transactions followed patterns that an SLM could safely verify. Savings amounted to $450,000 annually.
7.2. Legal Assistance Platform
Agents were required to analyze thousand-page documents. By applying the Reranking technology from AgentCore, context windows were shrunk from 100,000 tokens to 8,000 tokens while maintaining identical legal precision.
8. Security, Privacy, and Sovereign AI
Cost optimization must not come at the expense of security. AgentCore implements Local Privacy Filters.
8.1. On-Premise PII Scrubbing
Before data is sent to the cloud, AgentCore runs it through a local model that replaces names, addresses, and account numbers with anonymous tags. This not only increases security but also reduces the volume of data sent over the wire.
9. The Future: Toward “Zero-Marginal Cost” Intelligence
In the coming years, the key to success will be Hybrid Orchestration. AgentCore is evolving to support “Edge AI,” where part of the cognitive load is shifted directly to users’ mobile devices or local NPU-equipped laptops, reducing central cloud costs to a minimum.
Summary: 5 Steps to Immediate Savings
1. Model Audit: Stop using L3 models for classification and formatting. 2. Enable Caching: Take advantage of Prompt Caching from your providers. 3. Implement a Router: Start with simple semantic gating to filter easy requests. 4. Monitor CPS: Focus on the price per solved task, not the price per token. 5. Decompose RAG: Use rerankers to shrink the context provided to the LLM.
Conclusion
The AgentCore: Cost Optimization framework proves that artificial intelligence does not have to be a financial black hole. The key to success is:
• Don’t waste intelligence (use the right model tier). • Don’t forget (utilize semantic and prompt caching). • Filter ruthlessly (send only the essential text via RAG).
By implementing these principles, companies can build agents that are not only brilliant but, more importantly, economically sustainable.