Latest Mobile Dev Insights: iOS, Android, Cross-Platform |
MobilePro #222: Classical ML vs. Foundation Models: Picking the Right Tool |
|
|
|
Social engineering is about manipulating people's emotions. Identify the susceptibilities that hackers use to exploit people. |
This NINJIO Insights Report dives into the key emotional susceptibilities that make social engineering work and offers concrete steps that your security team can take to equip your workforce to resist cyberattacks. |
|
|
|
As Foundation Models dominate conversations around AI, it's easy to assume that every intelligent feature needs a large language model behind it.
In reality, many real-world mobile applications rely on a different kind of intelligence. Tasks like predicting checkout abandonment, detecting fraud, or forecasting user behavior are often better served by lightweight machine learning models that are faster, more efficient, and can run entirely on-device. Apple's Create ML and Core ML continue to make these solutions both practical and powerful.
In this week's article, Walid, the co-author of AI Driven Swift Architecture, explores the fundamental differences between classical machine learning and Foundation Models, explaining why choosing the right kind of intelligence matters more than simply choosing the biggest model. It's a timely reminder that the best AI solution is the one that fits the problem—not the hype.
|
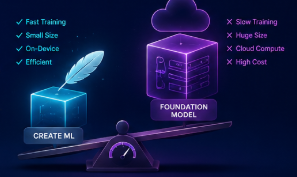
- Foundation Models aren't the right solution for every AI problem.
- Create ML excels at structured prediction tasks such as forecasting, classification, and recommendation.
- Classical ML models are lightweight, fast to train, and efficient enough to run entirely on-device.
-
Foundation Models shine for language understanding, reasoning, and generative experiences—not tabular prediction problems.
- The smartest engineering decision is choosing the model that best fits the problem, rather than defaulting to the largest AI model available.
|
|
|
|
-
Apple adds Google Gemini coding assistant in Xcode 26.6 update: Xcode 26.6 now supports Google Gemini as a third AI coding assistant, joining Anthropic Claude Agent and OpenAI Codex. The update also includes Swift 6.3.3, the latest platform SDKs, and support for additional agents via the Agent Client Protocol.
-
Apple acquired Swift Package Index: Swift Package Index, the community hub for discovering and evaluating Swift packages, has been acquired by Apple. The two will collaborate to build a comprehensive package registry serving the broader Swift ecosystem, including its expanding multi-platform reach across Linux, Android, and WebAssembly.
-
React Native 0.86: React Native 0.86 is out with full edge-to-edge display support on Android 15+ and React Native DevTools improvements. It's the second consecutive release with no breaking changes, making upgrades smoother for developers.
-
Google Play splits billing fees for US and European developers: Google Play is splitting its billing fees into separate service and transaction charges for developers in the US, UK, and EEA effective 30 June 2026, allowing them to use alternative payment gateways or external web links. The new tiered fee structure starts at 10% for the first $1M in annual earnings, with rates varying based on install type, payment method, and developer programme eligibility.
-
Anthropic cleared to release Claude Mythos 5 to over 100 US institutions: Following a US government export control directive that blocked access to its most powerful models, Anthropic has secured a partial reprieve allowing Claude Mythos 5 to be released to over 100 US institutions including major companies and government agencies. Claude Fable 5 remains restricted for now, though talks are reportedly moving toward its release as well.
|
|
|
|
Don't know where to find data and new ideas for your strategy? Subscribe to A Glitch in the Metrics newsletter, and you'll get fresh social media updates, real data, and viral trends (and it's also fun). 30k+ social media managers are already reading it. |
|
|
|
|
Walid SASSI began his iOS journey in 2011 while teaching distributed systems at the University of Carthage in Tunisia. Discovering the iPhone SDK sparked a growing interest that quickly became a professional focus. For nearly a decade, he combined academia with hands-on development, teaching computer science while working as an independent iOS developer. He built apps, mastered Swift and UIKit, and developed strong expertise in software architecture. Today, he is particularly interested in AI-assisted development and how it enhances productivity while maintaining solid engineering practices.
|
|
|
|
Create ML vs. Foundation Models: Choosing the Right Kind of Intelligence
|
For many developers today, artificial intelligence has become almost inseparable from Foundation Models, Transformers, and conversational systems capable of generating impressively human responses.
The industry conversation is now dominated by topics such as token prediction, context windows, embeddings, and reasoning models trained on enormous datasets.
But while experimenting recently with Create ML on a small checkout analytics dataset, I was reminded of something the current AI discourse sometimes tends to overlook: not every intelligent feature in an application requires a Foundation Model.
In many situations, classical machine learning remains not only sufficient, but also remarkably well adapted to the problem being solved.
The experiment itself was intentionally simple. I trained a predictive model using structured analytics collected from a fictional e-commerce checkout flow.
Each training row described a user session through features such as session duration, number of checkout steps, payment method, network retry count, cart size, previous checkout failures, and device type.
The target variable was binary: either the checkout completed successfully or the user abandoned the flow before purchase.
After importing the dataset into Create ML, training completed almost immediately. The resulting model was compact, lightweight, and ready to be integrated into an iOS application through Core ML.
What interested me most was not the prediction quality itself, but how fundamentally different this workflow is from the Foundation Model architectures we discuss so frequently today.
|
The Quiet Simplicity of Classical Machine Learning |
Create ML intentionally hides much of the mathematical complexity involved in training predictive systems.
From a developer’s perspective, the workflow is remarkably approachable: provide structured data, select a target column, train the model, evaluate the results, and export the generated .mlmodel file.
Behind this simplicity, however, lies a family of mature statistical techniques that have powered industrial prediction systems for decades.
Depending on the nature of the dataset, Create ML may rely on algorithms such as Linear Regression, Decision Trees, Random Forests, or Boosted Trees.
These models are not reasoning about language, maintaining conversational memory, or understanding semantic meaning. Instead, they learn statistical relationships between structured variables.
Over time, the model progressively discovers patterns hidden inside the data. Repeated network failures may correlate with checkout abandonment. Long checkout sessions may indicate friction in the purchase flow. Smaller carts may lead to lower conversion rates, while certain payment methods may correlate with faster completion.
This is supervised learning in its most classical form: structured inputs combined with known outcomes in order to learn patterns that can later generalize to unseen cases.
One particularly important metric during training is the Root Mean Square Error (RMSE), which measures how far predictions deviate from actual outcomes while heavily penalizing large errors. The model continuously adjusts its internal parameters in order to reduce this prediction error over time.
Perhaps the most surprising aspect of the experiment was how lightweight the entire process remained. Training completed in seconds, the resulting model footprint remained extremely small, and inference could execute entirely on-device.
This efficiency reflects the nature of the problem itself. Create ML was not attempting to train a generative system capable of reasoning over language or producing human-like responses.
It was solving a narrower and more structured prediction problem. And for many tabular prediction tasks, compact tree-based models remain extremely effective.
|
Why This Is Fundamentally Different from a Foundation Model
|
Although both systems belong to the broader field of machine learning, the architectural differences between Create ML models and Foundation Models are profound.
A checkout abandonment predictor has very little in common with a Transformer-based language model.
There is no tokenization, no contextual reasoning, no conversational memory, no attention mechanism, and no sequence modeling. The model simply learns correlations between structured features and observed outcomes.
Foundation Models operate in a very different domain. They are designed for problems involving language understanding, summarization, semantic interpretation, conversational interaction, and text generation.
Their architectures rely heavily on Transformers and self-attention mechanisms capable of modeling relationships between tokens across large context windows.
A tabular prediction model does none of this. And that distinction matters more than it might initially seem.
|
|
|
|
Many developers now unconsciously associate “modern AI” exclusively with large language models. But predicting whether a checkout session is likely to fail is fundamentally a statistical prediction problem rather than a language understanding problem.
Using a Foundation Model for such a task would often introduce unnecessary computational complexity, increased latency, larger memory requirements, and higher energy consumption, while potentially providing little practical benefit over a far smaller predictive model.
|
|
|
|
Smaller Models, Real Constraints |
|
|
|
One of the most interesting lessons from classical machine learning is that smaller systems are often better aligned with the operational realities of software engineering.
For structured business data, tree-based models frequently outperform neural networks while remaining dramatically smaller, faster to train, easier to deploy, and more energy efficient.
These characteristics align naturally with many of the engineering priorities that have historically shaped the Apple ecosystem: privacy, low latency, offline capabilities, and efficient on-device execution.
Foundation Models are transformative for generative interfaces and semantic reasoning. But many intelligent product features still belong firmly to the world of predictive machine learning.
Fraud scoring, engagement forecasting, recommendation ranking, checkout optimization, and churn prediction are often statistical systems before they are generative systems.
Apple now provides developers with two complementary forms of intelligence. On one side, Create ML and Core ML enable specialized predictive systems optimized for compactness and on-device execution.
On the other hand, Foundation Models introduce generative and contextual capabilities built upon Transformer architectures.
Interestingly, this also connects directly to Chapter 6 of my latest book, AI Driven Swift Architecture, with Dave Poirier on Packt Publishing, where we discuss Foundation Models and Transformer-based architectures in greater depth.
Looking at these two approaches side by side makes something increasingly clear: they are not competing versions of the same technology, but different tools designed for different categories of problems.
The interesting question is no longer whether applications should use AI, but which kind of intelligence actually fits the problem being solved. In many cases, the answer may be far simpler, and far smaller, than we initially expect.
|
If you’re exploring how AI-assisted workflows are reshaping real-world software engineering, AI-Driven Swift Architecture by Walid SASSI and Dave Poirier offers a practical look at building modern iOS systems with AI-assisted development, architecture patterns, concurrency, and production-ready engineering practices.
|
|
|
|
|
🧑💻 Master Clean Architecture, TDD, and modernization with Claude Code support
🛠️ Build SwiftUI apps powered by Apple Foundation Models and on-device intelligence
📱 Apply MCP workflows to create AI-driven feature agents in real projects
|
|
|
|
📢 Important: MobilePro is Moving to Substack |
We’ll be moving MobilePro to Substack soon. From that point forward, all issues will come from [email protected].
To ensure uninterrupted delivery, please whitelist this address in your mail client. No other action is required.
You’ll continue receiving the newsletter on the same weekly cadence, and on Substack you’ll also gain more granular control over your preferences if you wish to adjust them later.
|
|
|
|
Does every AI-powered feature really need a Foundation Model?
Reply and let me know.
|
|
|
|
Interested in sponsoring this newsletter and reaching a highly engaged audience of tech professionals? Simply reply to this email and our team will get in touch with next steps. |
Cheers,
Runcil Rebello,
Editor-in-Chief, MobilePro
|
Copyright (C) 2025 Packt Publishing. All rights reserved.
Our mailing address is:
Packt Publishing, Grosvenor House,
11 St Paul's Square, Birmingham,
West Midlands, B3 1RB, United Kingdom
Want to change how you receive these emails?
You can update your preferences or unsubscribe
|
|
|
|
|