Microsoft’s AI Controller Interface, MoE-LLaVA, SymbolicAI, BlackMamba, Time-LLM, Converting JSONs to Pandas DataF…
Data Labeling in ML with Python, Set up a local LLM on CPU with chat UI, Automate Labeling for Intelligent Document Processing, GNN in TensorFlow
Is this your brand on Milled? Claim it.
Microsoft’s AI Controller Interface, MoE-LLaVA, SymbolicAI, BlackMamba, Time-LLM, Converting JSONs to Pandas DataFrames, Eagle 7B, Data MaturityData Labeling in ML with Python, Set up a local LLM on CPU with chat UI, Automate Labeling for Intelligent Document Processing, GNN in TensorFlow
For DataPro Subscribers Only: Enter THE All-New PACKT LIBRARY! The Packt Library offers boundless, all-you-can-digest access to the premier independent learning hub in tech. Dive into a myriad of concepts at your whim, whenever you desire. It stands as the ultimate and flexible agile learning platform, ensuring you stay ahead of the curve in 2024.
Here are just a few of the many Data and AI titles we added last month: Unlock 50% off your first month today, exclusively for our valued newsletter subscribers. Limited time offer – act now! 👋 Hello, 🚀 Welcome to DataPro Newsletter #80 – your exclusive pass to the forefront of data science and AI innovation! Prepare to soar to new heights as we guide you through the latest insights and advancements, carefully curated to enrich your expertise and empower your journey. ⚡ Tech Tidbits: Stay Wired to the Latest Industry Buzz!
📚 The Newest Addition to Packt Library
🔍 From Bits to BERT: Keeping Up with LLMs & GPTs
✨ On the Radar: Catch Up on What's Fresh
DataPro Newsletter is not just a publication; it’s a comprehensive toolkit for anyone serious about mastering the ever-changing landscape of data and AI. Grab your copy and start transforming your data expertise today! 📥 Feedback on the Weekly Edition Take our weekly survey and get a free PDF copy of our best-selling book, "Interactive Data Visualization with Python - Second Edition." We appreciate your input and hope you enjoy the book! Cheers, Sign Up | Advertise | Archives 🔰 GitHub Finds: Any of These Repos in Your Toolbox?🌀 bclavie/RAGatouille: RAGatouille simplifies using advanced retrieval methods in RAG pipelines, bridging research and practice, optimizing performance by enhancing retrieval models. 🌀 allenai/OLMo: OLMo is an AI2 repository for advanced language models, designed by scientists. Installation begins with PyTorch setup tailored to your OS. 🌀 deepseek-ai/DeepSeek-Math: DeepSeekMath utilizes DeepSeek-Coder-v1.5 7B, pre-training on math tokens from Common Crawl alongside natural language and code data, achieving 51.7% on MATH benchmark. 🌀 apple/ml-mgie: This repository presents MLLM-Guided Image Editing (MGIE), leveraging multimodal large language models for improved instruction-based image manipulation. 🌀 nomic-ai/contrastors: Efficient toolkit for training and evaluating contrastive models, featuring Flash Attention, multi-GPU support, and Huggingface compatibility. 🌀 Eladlev/AutoPrompt: Auto Prompt optimizes prompts for real-world applications, generating tailored prompts and refining them iteratively to reduce manual effort and address common issues. 📚 Expert Insights from Packt CommunityData Labeling in Machine Learning with Python - By Vijaya Kumar Suda Understanding the ML project life cycle
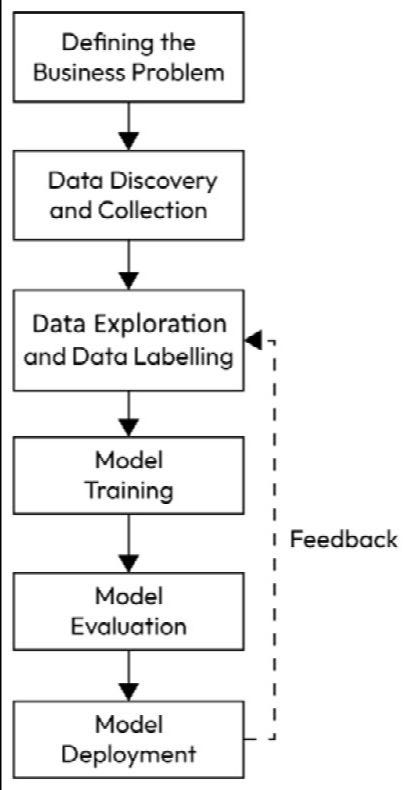
Defining the business problem The first step in every ML project is to understand the business problem and define clear goals that can be measured at the end of the project. Data discovery and data collection In this step, you identify and gather potential data sources that may be relevant to your project’s objectives. This involves finding datasets, databases, APIs, or any other sources that may contain the data needed for your analysis and modeling. The goal of data discovery is to understand the landscape of available data and assess its quality, relevance, and potential limitations. Data exploration Data exploration follows data discovery and is primarily focused on understanding the data, gaining insights, and identifying patterns or anomalies. During data exploration, you may perform basic statistical analysis, create data visualizations, and conduct initial observations to understand the data’s characteristics. Data exploration can also involve identifying missing values, outliers, and potential data quality issues, but it typically does not involve making systematic changes to the data. Data labeling Data labeling involves acquiring or generating more labeled examples to supplement your training dataset. You may need to manually label additional data points or use programming techniques such as data augmentation to expand your labeled dataset. The process of assigning labels to data samples is called data annotation or data labeling. After obtaining a sufficient amount of labeled data, you proceed with traditional data preprocessing tasks, such as handling missing values, encoding features, scaling, and feature engineering. Model training Once the data is adequately prepared, then that dataset is fed into the model by ML engineers to train the model. Model evaluation After the model is trained, the next step is to evaluate the model on a validation dataset to see how good the model is and avoid bias and overfitting. You can evaluate the model’s performance using various metrics and techniques and iterate on the model-building process as needed. Model deployment Finally, you deploy your model into production and monitor for continuous improvement using ML Operations (MLOps). MLOps aims to streamline the process of taking ML models to production and maintaining and monitoring them. This is where Python helps us to explore and perform a quick analysis of raw data using various libraries (such as Pandas, Seaborn, and ydata-profiling libraries), otherwise known as EDA. This excerpt is from the newly released book, "Data Labeling in Machine Learning with Python" by Vijaya Kumar Suda, published in January 2024. Dive into the free chapter for a preview of the content. ⚡ Tech Tidbits: Stay Wired to the Latest Industry Buzz!AWS ML Made Easy🌀 Accenture creates a regulatory document authoring solution using AWS generative AI services: Accenture developed an AI-powered solution for pharmaceutical companies to streamline the labor-intensive process of creating Common Technical Documents (CTDs) for FDA submissions. By leveraging Amazon SageMaker JumpStart and AWS AI services, the system automates document generation while ensuring data security and compliance. This innovation accelerates drug approvals, benefiting patients and advancing pharmaceutical efficiency. 🌀 Automate Labeling for Intelligent Document Processing with Inawisdom and Amazon SageMaker Ground Truth: Intelligent Document Processing (IDP) automates data extraction from various documents, enhancing speed, accuracy, and cost-effectiveness compared to manual methods. Inawisdom's IDP solution on AWS addresses challenges like labeling large datasets, ensuring ML model accuracy, and integrating training data with inference pipelines, enabling efficient document processing. Mastering ML with Google🌀 Graph neural networks in TensorFlow: The post discusses the significance of relationships between objects in various contexts, highlighting the limitations of traditional machine learning algorithms in handling irregular connections. It introduces Graph Neural Networks (GNNs) as a powerful technique for analyzing and making predictions on graph structures and announces the release of TensorFlow GNN 1.0 (TF-GNN) as a production-tested library to support building GNNs at scale. 🌀 A decoder-only foundation model for time-series forecasting: The blog demonstrates the importance of time-series forecasting across industries and introduces TimesFM, a foundation model trained on vast time-series data for accurate forecasting. It highlights the model's effectiveness in providing out-of-the-box forecasts without additional training, aiming to enhance retail demand planning and other applications. Microsoft Research Insights🌀 AI Controller Interface: Generative AI with a lightweight, LLM-integrated VM. This research focuses on addressing challenges associated with large language models (LLMs), particularly regarding content accuracy, compliance, and security in sensitive sectors like healthcare and finance. The proposed solution, the AI Controller Interface (AICI), facilitates seamless integration, customization, and security for LLMs, enhancing their usability and reliability. Email Forwarded? Join DataPro Here! 🔍 From Bits to BERT: Keeping Up with LLMs & GPTs🌀 MoE-LLaVA: Mixture of Experts for Large Vision-Language Models. This work introduces MoE-Tuning, a training strategy for Large Vision-Language Models (LVLMs), addressing performance degradation in multi-modal sparsity learning. The proposed MoE-LLaVA architecture activates top-k experts during deployment, demonstrating significant performance in visual understanding and object hallucination benchmarks. 🌀 SymbolicAI: A framework for logic-based approaches combining generative models and solvers. SymbolicAI is a versatile framework for integrating generative models with logic-based concept learning. It bridges symbolic reasoning with generative AI, enabling tasks execution through natural and formal language instructions, employing probabilistic programming principles, and introducing a quality measure for evaluating computational graphs. 🌀 BlackMamba: Mixture of Experts for State-Space Models. BlackMamba, blending State-space models (SSMs) with mixture-of-expert (MoE), offers competitive performance and efficient inference, combining linear-complexity generation with reduced compute costs. Fully trained models and code are open-source. 🌀 Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. Time-LLM reprograms large language models (LLMs) for time series forecasting by aligning time series data with text prototypes. It outperforms specialized models, excelling in both few-shot and zero-shot learning scenarios. 🌀 Weaver: Foundation Models for Creative Writing. Introducing Weaver, a family of large language models (LLMs) tailored for content creation, ranging from Weaver Mini to Weaver Ultra. Weaver outperforms generalist LLMs, with the Ultra model surpassing GPT-4 in various writing scenarios. It supports retrieval-augmented generation and function calling for enhanced AI-assisted writing systems. 🌀 Eagle 7B: Soaring past Transformers with 1 trillion Tokens Across 100+ Languages (RWKV-v5). Eagle 7B, based on RWKV-v5 architecture, is a highly efficient 7.52B parameter model with lower inference costs, outperforming others in multilingual benchmarks. It's released under Apache 2.0 license, available for personal or commercial use, and downloadable from Huggingface. ✨ On the Radar: Catch Up on What's Fresh🌀 OpenAI API for Beginners: Your Easy-to-Follow Starter Guide. The tutorial introduces OpenAI API for various applications, focusing on easy setup and usage for text generation, multiturn chat, embeddings, transcription, translation, text-to-speech, vision, and image generation tasks, making AI accessible even for beginners. 🌀 Converting JSONs to Pandas DataFrames: Parsing Them the Right Way. This tutorial explores parsing JSON data into tabular format using Python's Pandas library, focusing on the pd.json_normalize() function. It covers handling simple and multi-level JSONs, dealing with null values, selecting specific columns, and managing nested lists within JSON fields. 🌀 Data Maturity: The Cornerstone of AI-Enabled Innovation. Businesses increasingly leverage AI for operational optimization and decision-making, but data maturity remains essential for maximizing AI benefits. Challenges like data silos and quality hinder AI adoption. Prescriptive strategies, including data democratization, effective governance, and AI-driven data curation, are pivotal for establishing a robust data foundation to scale AI capabilities. 🌀 3 Key Encoding Techniques for Machine Learning: A Beginner-Friendly Guide with Pros, Cons, and Python Code Examples. The article explores various encoding techniques essential in machine learning, focusing on their importance, implementation, advantages, and disadvantages. It covers label encoding, one-hot encoding, and target encoding, offering practical examples and tips for data scientists. 🌀 Machine Learning Algorithms as a Mapping Between Spaces: From SVMs to Manifold Learning. The article delves into the concept of "spaces" in machine learning, highlighting their significance in understanding algorithms' data processing. It discusses feature spaces, challenges in low-dimensional spaces, and various techniques like Support Vector Machines, Autoencoders, and manifold learning to navigate and interact between different spaces. 🌀 A Data Mesh Implementation: Expediting Value Extraction from ERP/CRM Systems: The article discusses the challenges faced by data engineers in bridging the gap between raw operational data and domain knowledge, particularly in ERP and CRM systems. It introduces the concept of source-aligned data products within a Data Mesh framework to streamline data accessibility and ownership. 🌀 Set up a local LLM on CPU with chat UI in 15 minutes: The tutorial guides users through setting up local, performant large language models (LLM) with ChatGPT-like UIs, enabling interaction without third-party data transmission, in four simple steps. See you next time! As a GDPR-compliant company, we want you to know why you’re getting this email. The _datapro team, as a part of Packt Publishing, believes that you have a legitimate interest in our newsletter and its products. Our research shows that you opted-in for email communication with Packt Publishing in the past and we think your previous interest warrants our appropriate communication. If you do not feel that you should have received this or are no longer interested in _datapro, you can opt out of our emails by clicking the link below. |